"A Beginners Guide to Structured Query Language (SQL)" Part 2

I am an elect/elect student and a data scientist. I love AI and all you can do with it and want to apply it in my course of study. I would also like to see more of data science and AI applications in the health sector.
Welcome back, guys!!
So in the last post of this series, we saw how to select columns and filter rows to obtain results from a relational database using the SQL syntax in simple ways. That was the first thing to know about writing queries and extracting data from a database using SQL syntax. In this article, we are going to walk through the steps of using aggregate functions to summarize data and gain useful insights, how to deal with missing values, sorting and grouping the results gotten from our queries and we will also see how to use aliasing to make results more readable.
In case, you are just getting started on SQL, you can check out the first article in this series. It contains a brief introduction to SQL and the pre-requisites needed for it. This is the link to the article: https://jamesfav.hashnode.dev/a-beginners-guide-to-structured-query-language-sql
TABLE OF CONTENTS
- COUNT statement
- Aliasing
- IS NULL and IS NOT NULL
- Aggregate functions(sum, average, etc)
- Sorting and Grouping Results
The dataset used in this article is the IMDB movies dataset and I made use of only the title, language, genre, votes, duration and year columns. The dataset can be gotten from here: kaggle.com/stefanoleone992/imdb-extensive-d.. Now we know what we will be doing, let us now proceed without much ado.
1. COUNT: The count statement is used to know the number of rows in one or more columns. You can use it to know how many rows are in the whole table. we can do this with the following code.
SELECT COUNT(*) FROM IMDb_movies_csv;
This will produce the following result;
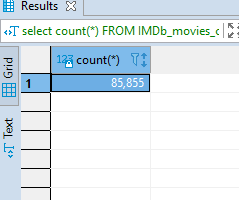
You can also use the COUNT statement to know the number of rows in a specific column. Let us count the number of rows in the title column.
SELECT COUNT(title) FROM IMDb_movies_csv;
Observe the result and compare the result gotten when we counted all the rows.
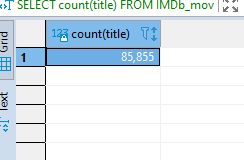
You will notice it gave us the same number as when we counted all the rows. This is because all the movies have titles, that is, no null row in the title column.
You can also combine COUNT with DISTINCT to know the number of distinct values in a column. Let us count the number of distinct titles and observe the difference.
SELECT COUNT(DISTINCT title) FROM IMDb_movies_csv;
This will give a slightly different result;
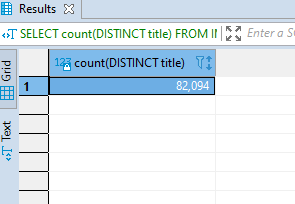
Note that you can also COUNT the rows based on a specific condition using the WHERE statement. For example, let us count the number of movies where the language used is English.
SELECT COUNT(title) FROM IMDb_movies_csv
WHERE language = 'English';
See what this gives us;
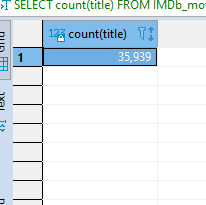
Now we have seen the different things we can do with the COUNT statement, you can try out different things yourself. Let us move on to aliasing.
2. Aliasing: If you compare the result gotten when you counted the number of rows in the title columns and the result got when you counted the number of rows for English movies, you will notice the heading is the same which is COUNT(title). We will have two columns called that and this can confuse. To prevent this, SQL allows you to assign temporary names to results. This is called "ALIASING". Using the same example I mentioned above, let us see how we can alias the result heading.
First, let us count all the rows in the title column, that is all the movies.
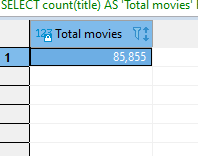
SELECT count(title) AS 'Total movies'
FROM IMDb_movies_csv;
This will give the following result;
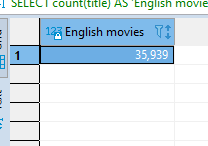
Now, let us count the rows in the title column that the language used is English. That is English movies.
SELECT count(title) AS 'English movies'
FROM IMDb_movies_csv
WHERE language = 'English';
This gives the following result;
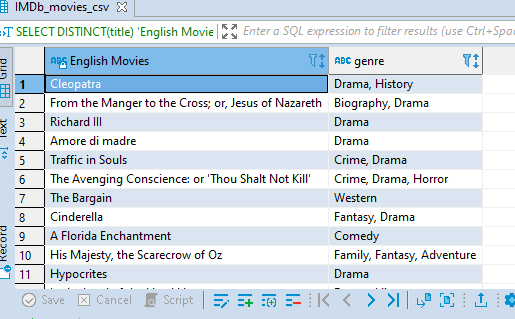
Note: You can alias anything, even the table and column names and you don't need to use 'AS' all the time. Aliasing helps us to write shorter queries but make sure to use unique names while aliasing so you cannot mix things up and you can note it somewhere what the alias stands for in case you will want to come back to the query result another time. Let us see one last example without using 'AS'.
SELECT DISTINCT(title) 'English Movies', genre
FROM IMDb_movies_csv imc
WHERE language = 'English';
 Aliasing comes in very handy when dealing with joins between different tables and when you are dealing with many queries and subqueries. It will help you in such a way that you won't need to write the column or table names every time you refer to it and it also helps prevent ambiguity in case two columns of different tables have the same names. We will see this in the last article of this series.
Aliasing comes in very handy when dealing with joins between different tables and when you are dealing with many queries and subqueries. It will help you in such a way that you won't need to write the column or table names every time you refer to it and it also helps prevent ambiguity in case two columns of different tables have the same names. We will see this in the last article of this series.
3. IS NULL and IS NOT NULL statements: To know the missing values you have in a table, SQL has the IS NULL statement to do this. You use it with the where statement when filtering the result. Let us see movies that having missing entries in the language column.
SELECT title, language
FROM IMDb_movies_csv
WHERE language IS NULL;
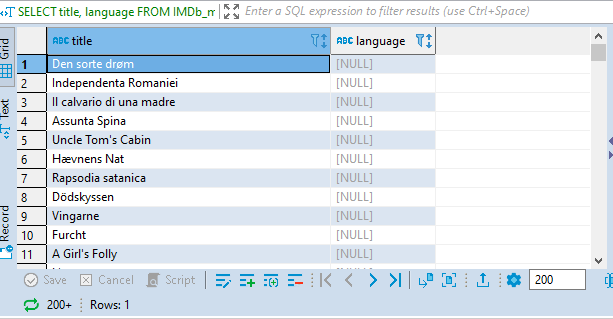
You can also select values that are not missing. Let us see the movies that don't have missing entries in the language column.
SELECT title, language
FROM IMDb_movies_csv
WHERE language IS NOT NULL;
4. Aggregate functions: There are a bunch of aggregate functions that can be used in SQL to perform some calculation on data in a database. We are going to see how to use SUM, AVG, MAX and MIN.
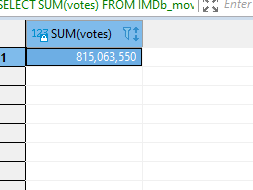
The SUM function does what its name says. It adds up the numeric values in a column. Let us get the total votes of all the movies.
SELECT SUM(votes)
FROM IMDb_movies_csv;
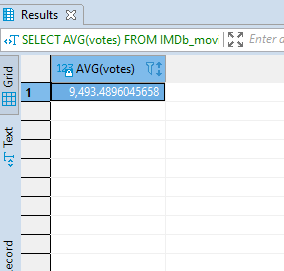
 The average function is just used to calculate the average of values in a column. Let us see the average of all the votes for the movies.
The average function is just used to calculate the average of values in a column. Let us see the average of all the votes for the movies.
SELECT AVG(votes)
FROM IMDb_movies_csv;
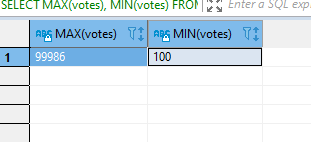
 The max and min functions are used to get the highest and lowest values in a column of a table. Let us get the highest and lowest votes of movies.
The max and min functions are used to get the highest and lowest values in a column of a table. Let us get the highest and lowest votes of movies.
SELECT MAX(votes), MIN(votes)
FROM IMDb_movies_csv;
You can also use all these aggregate functions with the WHERE statement. Now that we have seen the basic way of using our aggregate functions, let us move to the last one for the day which is how to order our results.
5. Sorting and Grouping Results: In SQL, we use the statement ORDER BY to arrange our results in ascending or descending order according to the values in one or more columns. Let's see arrange the movies according to the year they were released, from the first year.
SELECT title, genre, year
FROM IMDb_movies_csv
ORDER BY year;
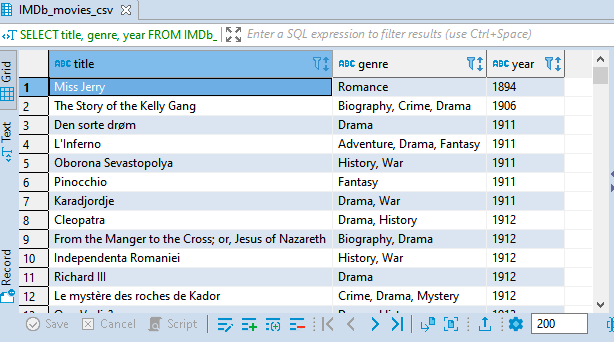
Normally, ORDER BY arranges the result in ascending order, that is from smallest to biggest. To arrange our results in descending order, we use the keyword DESC after the column name. Let's try to order the example above in descending order, that is from the last year.
SELECT title, genre, year
FROM IMDb_movies_csv
ORDER BY year DESC;
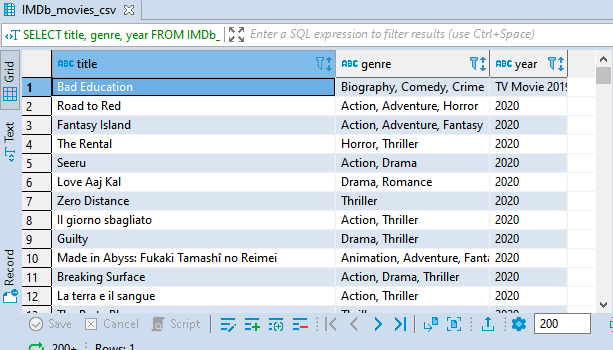
You can also order your results by more than one column. You just have to write the column names in the order you want the results to be sorted by. The results will sort by the first column followed by the second and so on. This means the order of the column names matter. Let's see an example;
SELECT title, genre, year
FROM IMDb_movies_csv
ORDER BY year, duration;
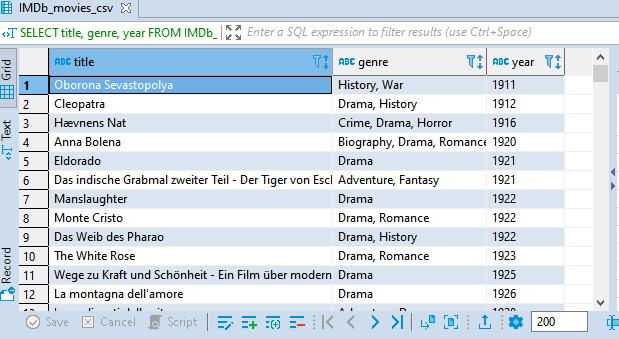
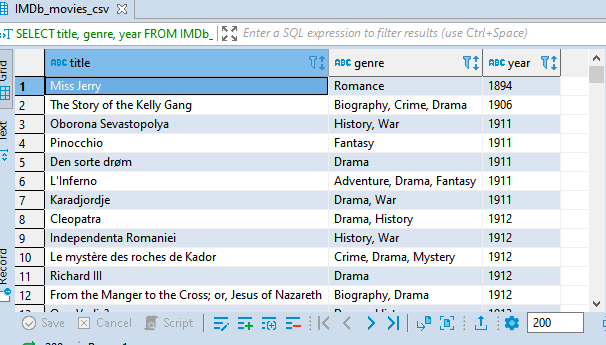 Notice what happens when the column names arrangement is changed.
Notice what happens when the column names arrangement is changed.
SELECT title, genre, year
FROM IMDb_movies_csv
ORDER BY duration, year;
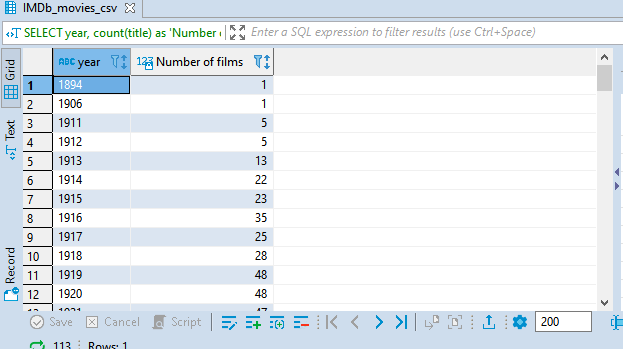
 Now to the last one for the day, the statement GROUP BY. Let us say we want to count the number of movies made per year. This is where that statement comes in. Group by is used to aggregate results, that is to perform calculations per group. GROUP BY is normally used with aggregate functions.
Now to the last one for the day, the statement GROUP BY. Let us say we want to count the number of movies made per year. This is where that statement comes in. Group by is used to aggregate results, that is to perform calculations per group. GROUP BY is normally used with aggregate functions.
SELECT year, count(title) as 'Number of films'
FROM IMDb_movies_csv
group by year;
So, we have come to the end of this article. Remember, practice makes perfect. If you are just starting on this, it may seem confusing and all but trust me, with time, practice and consistency, you can get it. Just take one step at a time and soon, you will be a pro. Watch for the last of this series, we will be considering JOINS in SQL. I hope you enjoy the read and give it a clap if you found it helpful. Don't hesitate to leave your comments and questions too.
I'm also open for connections. Follow me on twitter: @FavourJhay


